Motivation
In service robotics, verbal communication allows non-expert users to naturally express their needs. However, speech-based robot programming remains limited by ambiguity, speech recognition errors, and difficulty describing spatial movements verbally. While visual aids are widely used in human-to-human communication to enhance comprehension, their potential in human-robot interaction remains underexplored. GenComUI investigates how dynamically generated visual aids can serve as a communication medium to bridge the gap between natural language instructions and robot understanding.

Formative Study
To inform the design of GenComUI, we conducted an observational study examining how humans use external visual tools (paper maps and pens) to assist verbal communication in spatial tasks. The study revealed three key design considerations: (DC1) visual aids should provide timely and progressive feedback during communication; (DC2) visual aids should interpret and externalize user task intentions; (DC3) visual aids should integrate with speech to improve clarity and intuitiveness; (DC4) the system should support iterative task refinement through visual confirmation.

GenComUI System
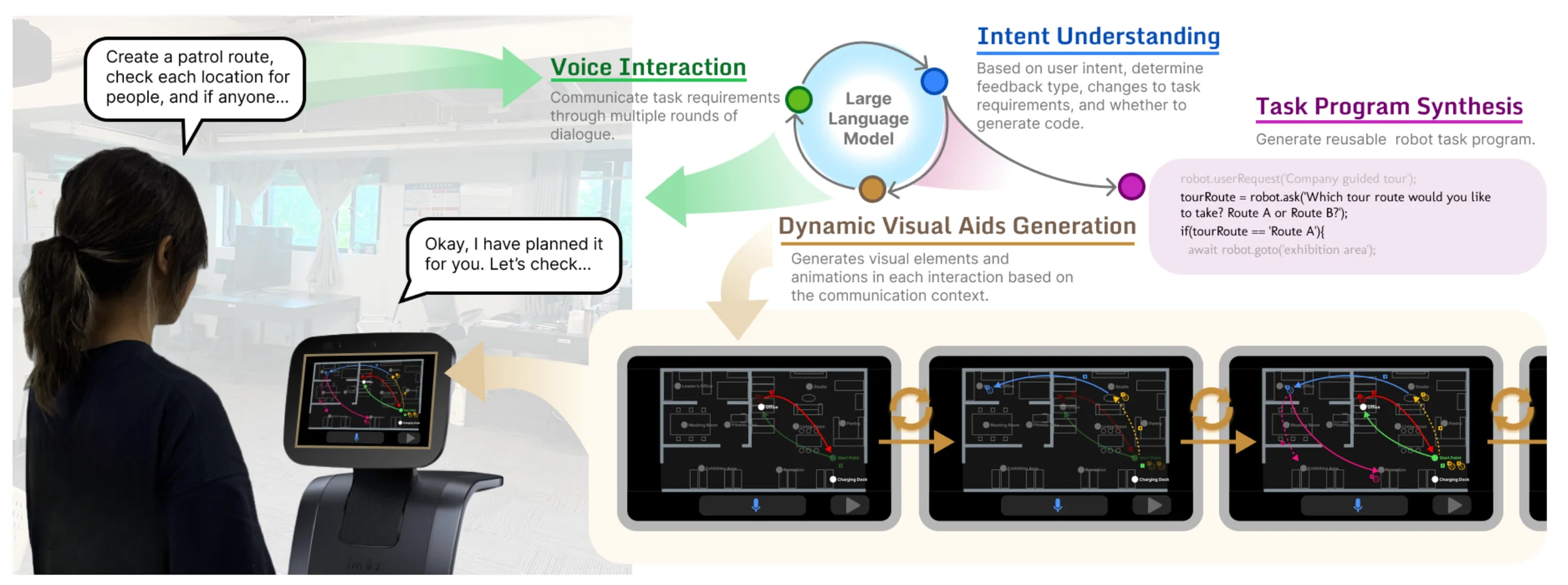
Based on the design considerations, we developed GenComUI, an LLM-based robot end-user development system that incorporates generative visual aids. Implemented on the Temi V2 robot, the system consists of four core modules:
- Voice Interaction Module: Handles bidirectional voice communication via speech-to-text and text-to-speech conversion.
- User Intention Understanding Module: Analyzes input and dialogue context to track task specifications and plan responses, including visual aid generation.
- Generative Visual Aids Module: Generates visual interface elements and animations on spatial maps according to the communication context.
- Task Program Synthesis and Deployment Module: Generates and deploys executable robot code with built-in testing for iterative refinement.


User Study
We conducted a within-subjects user study with 20 participants (12 female, 8 male, aged 18–60) comparing GenComUI with a voice-only baseline system. Participants completed tasks in a simulated office environment using both systems in counterbalanced order, combining think-aloud protocols with semi-structured interviews.
The results showed that generative visual aids enhanced communication quality by providing immediate feedback and supporting iterative refinement of task specifications. While visual aids did not significantly reduce task completion time, they promoted more natural and effective human-robot communication, particularly in complex tasks involving spatial movements and multi-step logic.
